What difference is there between the A* algorithm and Dijkstra’s algorithm? (in terms of nodes explored)
The difference between A* and Dijkstra’s algorithm in terms of nodes explored is that A* is less greedy and has a more educated guess h, the heuristic functions that helps us lessen the nodes explored. In Dijkstra’s, as it is a greedy algorithm, we would have to traverse and visit, at worse case, all the nodes, as we would have to find the shortest path. This would really take time and is inefficient. With the heuristic function of A*, we can be always near the end point when we visit and go to the different nodes, and the next node after that, and so on. A* is more efficient and takes less routes, meaning, less nodes are explored, as compared to Dijkstra’s algorithm.
Try illustrating a graph from the sample input and show the path A* takes.
Below is the illustration of the path of the algorithm for the first sample test case. Below is the coded example and a diagram. After it will be the steps the algorithm will take.
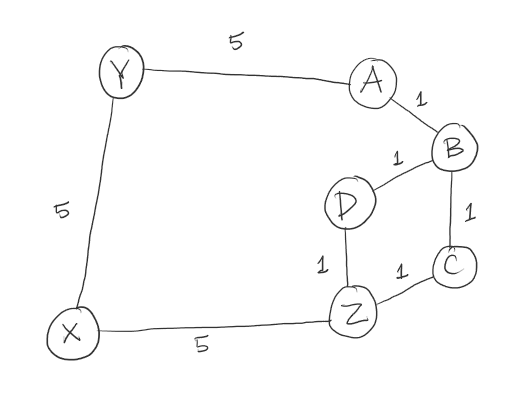
A* Steps:
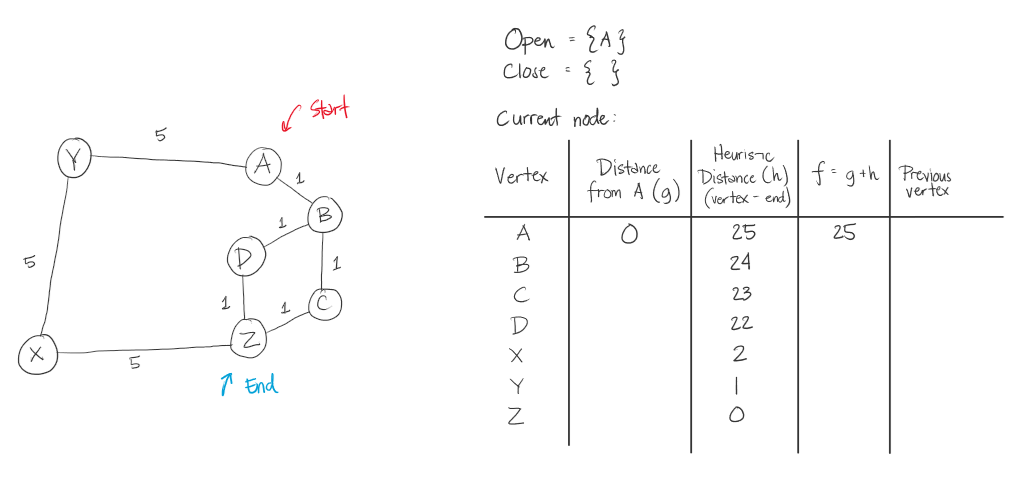
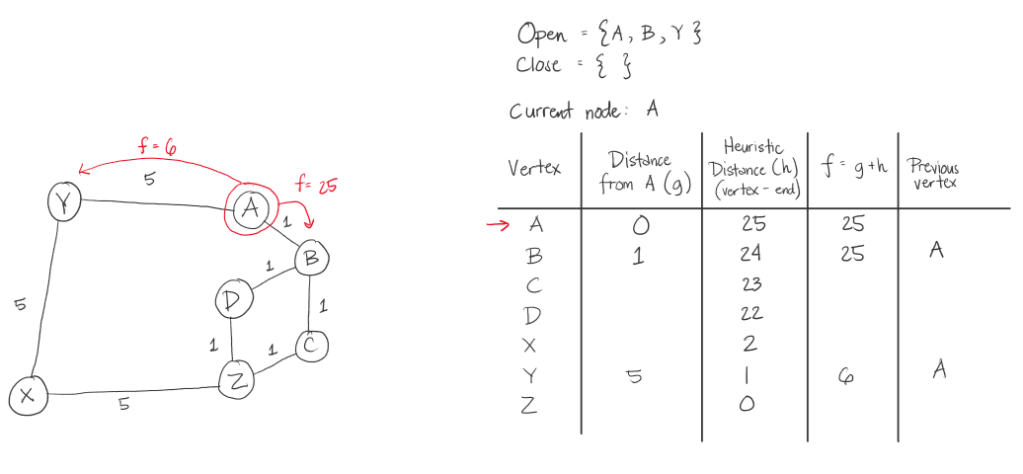
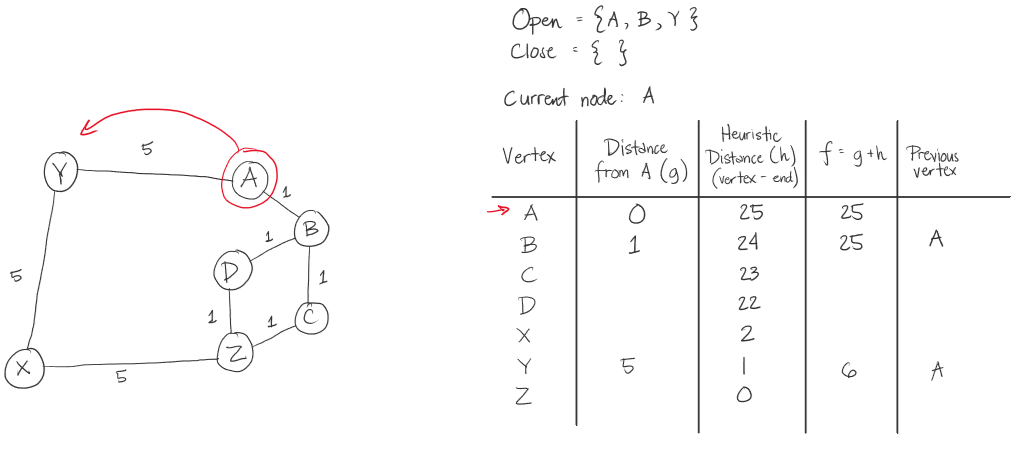
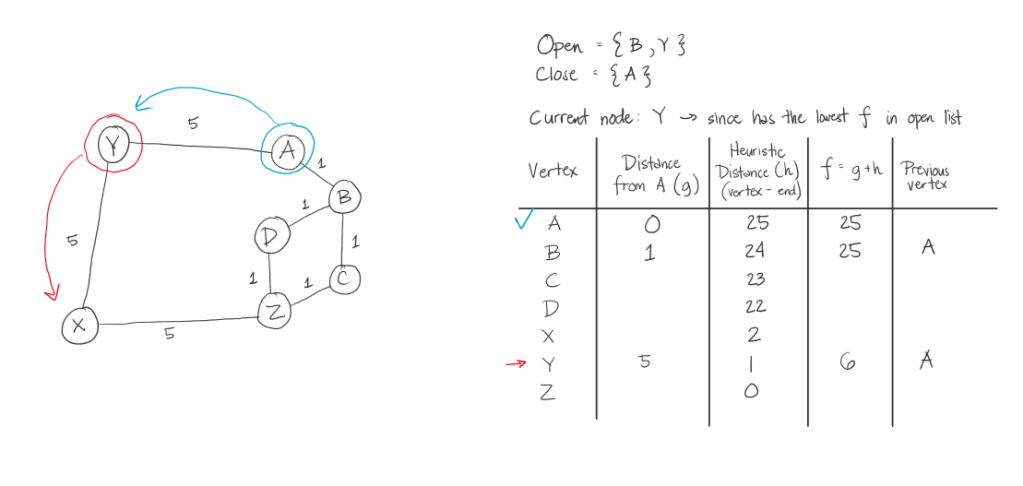
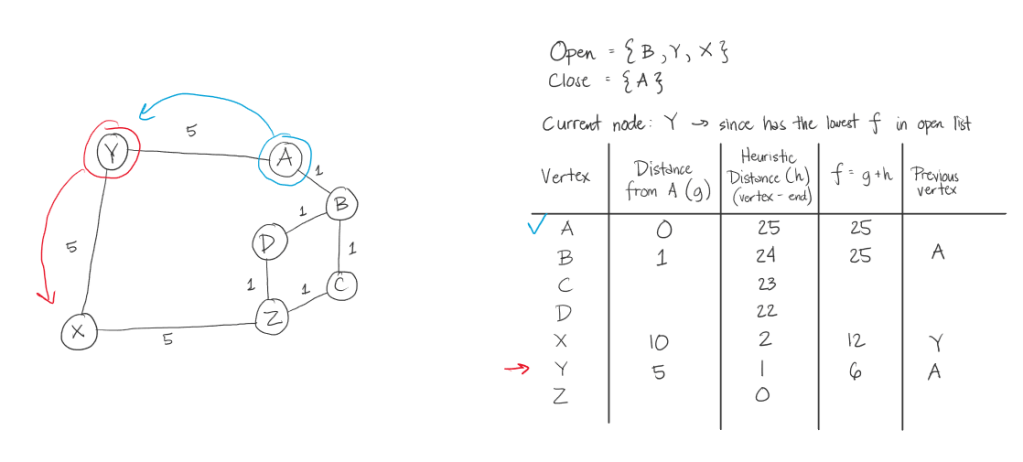
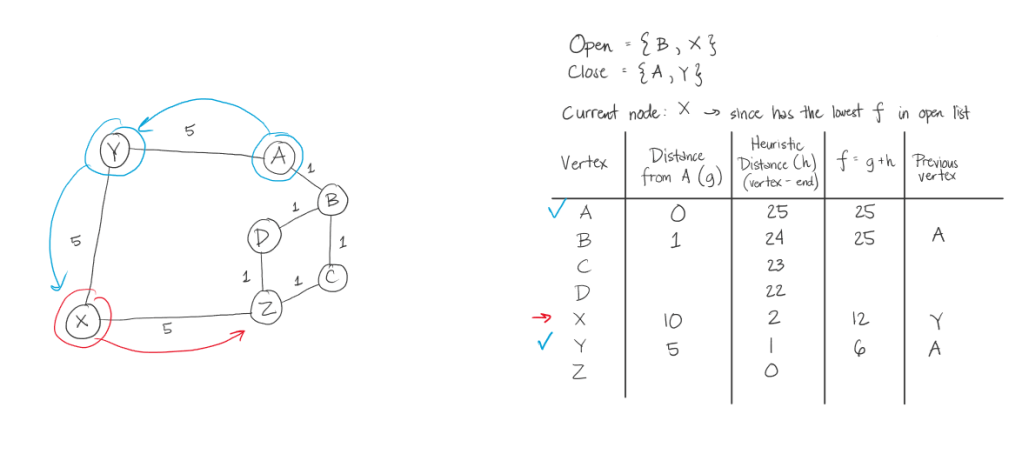
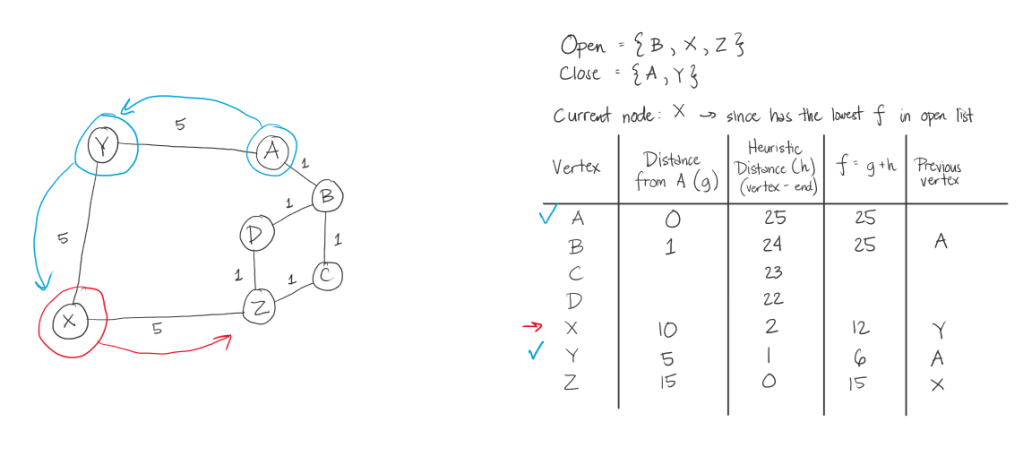
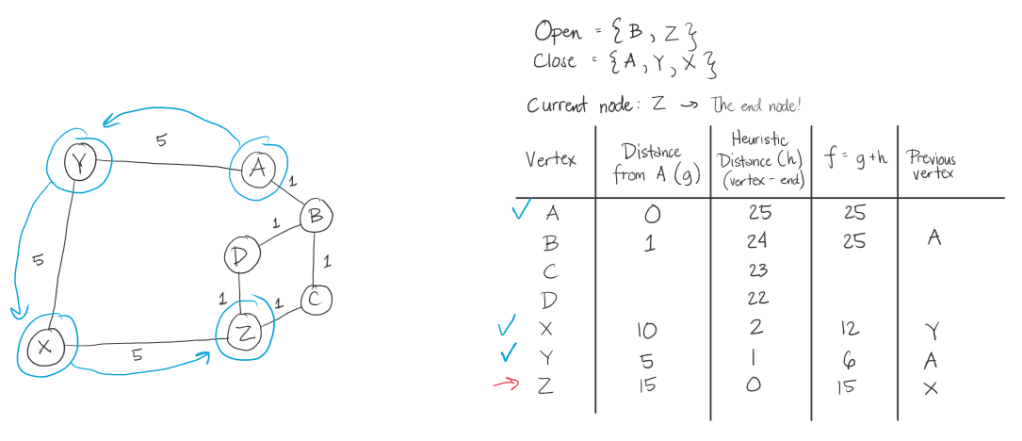

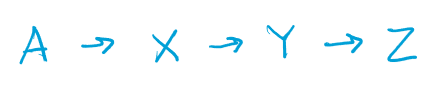
The thing that makes this A* algorithm inefficient in this case, is that we took the heuristic value of the distance of the letter from the target letter. This made going from A to Z, in this example, its weight significantly bigger than if we were to just see the graph and get at least 3 in weight. In here, we had 15.
Code Used:
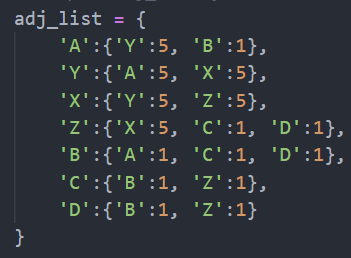
# sample adj_list for test case 1
# adj_list = {
# 'A':{'Y':5, 'B':1},
# 'Y':{'A':5, 'X':5},
# 'X':{'Y':5, 'Z':5},
# 'Z':{'X':5, 'C':1, 'D':1},
# 'B':{'A':1, 'C':1, 'D':1},
# 'C':{'B':1, 'Z':1},
# 'D':{'B':1, 'Z':1}
# }
class Graph:
def __init__(self):
self.adj_list = {}
def addEdge(self, i, j, w):
if i in self.adj_list:
self.adj_list[i].update({j:w})
else:
self.adj_list[i] = {j:w}
if j in self.adj_list:
self.adj_list[j].update({i:w})
else:
self.adj_list[j] = {i:w}
def adjacentVertex(self, vertex):
return self.adj_list[vertex]
def h(self, start, end):
return abs(ord(start) - ord(end))
def aStar(self, start, end):
open_list = set([start]) # list of nodes that have been visited, BUT the neighbors of the nodes haven't all been inspected; it starts off with the start node
closed_list = set([]) # list of nodes that have been visited, BUT the neighbors ARE inspected
g = {} # this contains the current distances from the start node to all other nodes
g[start] = 0 # the distance of the start node to itself is 0
adjacency_map = {} # contains the key-value pair of the edge(start_node with its adjacent vertex;
# basically the parent/previous node of the nodes that go from start to end) going to the end node
adjacency_map[start] = start # starts off with the start node with its value pair as itself
while len(open_list) > 0:
current_node = None # This will be the node we will keep track in going through each path of the graph
# selects the current node based on f = g + h
for vertex in open_list: # this checks for the node of the lowest value of the f, which is f = g + h, of the current node and the vertex in the open list
if current_node == None or g[vertex] + self.h(vertex, end) < g[current_node] + self.h(current_node, end):
current_node = vertex # the current node will be the vertex that is has the lowest value of f
if current_node == None: # when the path doesn't exist, return None
print('Path does not exist.')
return None
if current_node == end: # if our current_node is already at our end node, we will create a list of the path taken
path_taken = []
while adjacency_map[current_node] != current_node: # takes in the value of the end node's previous node and append it to the list
path_taken.append(current_node)
current_node = adjacency_map[current_node]
path_taken.append(start)
path_taken.reverse() # since the list path taken is from the end node to the start, this reverses that order of that list
# print(adjacency_map)
# print()
for path in path_taken:
print(path, end=' ') # prints out the path
return path_taken
for neighbor in list(self.adjacentVertex(current_node).keys()): # this checks for each neighbor and weight of the current node
weight = self.adjacentVertex(current_node)[neighbor] # gets the weight of the neighbors
if neighbor not in open_list and neighbor not in closed_list: # if this neighbor is not in both open_kist and closed_list, adds to the open list and note the the current node we are in is its parent
open_list.add(neighbor)
adjacency_map[neighbor] = current_node # takes note of the previous/parent node of the neighbor
g[neighbor] = g[current_node] + weight # takes note of the value of the weight of this node (neighbor) from the starting vertex
else: # or if it's in either, check if it's faster to visit the current node first, and then its neighbor;
if g[neighbor] > g[current_node] + weight: # if yes, update the parent data and neighbor data
g[neighbor] = g[current_node] + weight
adjacency_map[neighbor] = current_node
if neighbor in closed_list: # if the neighbor node is in the closed list, move it to the open_list
closed_list.remove(neighbor)
open_list.add(neighbor)
open_list.remove(current_node) # removes the current from the open list, since we have checked its neighbors;
closed_list.add(current_node) # and we put them in the closed list
print('Path does not exist.') # if we've exhausted every possible path taken and every thing is already possible path in the closed list, return None
return None
input_dat = []
# reading input.dat
with open('input.dat', 'r') as input:
input.readline()
for line in input:
input_dat.append(line.split())
# print(input_dat)
for i in input_dat:
input_dat_edges = i[1:-2]
start = i[-2]
end = i[-1]
edges = [input_dat_edges[j:j+3] for j in range(len(input_dat_edges)) if j % 3 == 0]
graph = Graph()
for edge in edges:
graph.addEdge(edge[0], edge[1], int(edge[2]))
# print()
# print(edges)
# print(graph.adj_list)
graph.aStar(start, end)
print()
# print(test_cases)
# for reference, I used these websites
# https://stackabuse.com/basic-ai-concepts-a-search-algorithm/
# https://www.youtube.com/watch?v=eSOJ3ARN5FM&t=12sSample Input
2
8 A Y 5 Y X 5 X Z 5 A B 1 B C 1 B D 1 C Z 1 D Z 1 A Z
8 A B 2 B D 1 B C 2 F C 7 C E 2 F E 1 D G 3 E G 2 A FSample Output
A Y X Z
A B C E F